
Problem Definition
Energy trading requires precise forecasting of power consumption to manage supply-demand imbalances, optimize trading decisions, and mitigate price volatility. Renewable energy sources, while sustainable, introduce unpredictability due to their dependency on weather conditions. As a result, Pure Energie requires short-term forecasts of the total energy consumption of all customers. This ensures efficient electricity trading by enabling precise buying and selling decisions.
Goal
The goal of this project is to design and implement a machine learning pipeline that accurately forecasts power consumption and production for Pure Energie customers 1 to 48 hours into the future. By integrating weather data from the KNMI and applying modern MLOps practices, the pipeline enables better decision-making for energy trading, helping Pure Energie optimize electricity purchases and sales.
Data Ingestion Pipeline
In our pipeline, we begin by downloading .tar files from the KNMI platform, which contain weather forecast data in .grib format. After extracting these files, we retain only the first-hour forecast entries for training. The .grib files are stored in MinIO for efficient object storage. From there, we retrieve the data, transform it into a usable tabular format, and store key variables in InfluxDB to enable high-performance time-series analysis. This processed data serves as the input for our prediction models. Since we do not have continuous access to allocation (consumption) data, model training is handled in a separate pipeline and must be manually triggered whenever new allocation data becomes available.
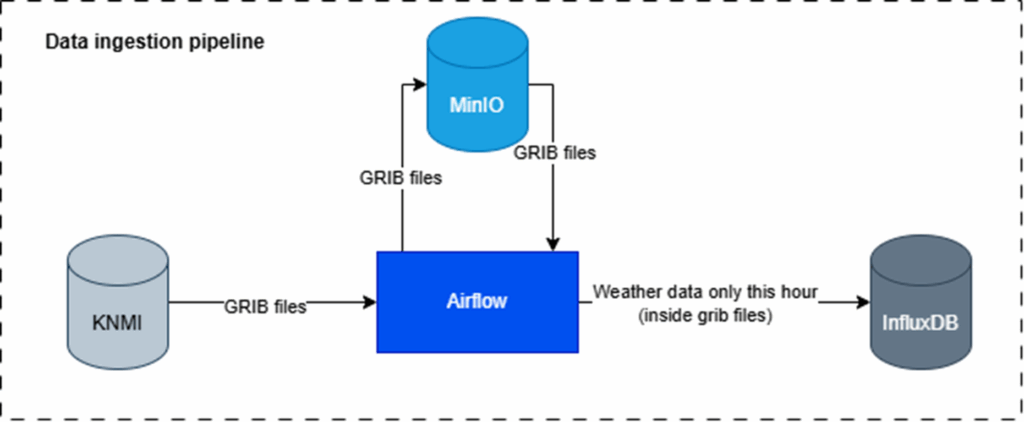
Whenever new weather data comes in, we make predictions for energy usage for the next 60 hours:
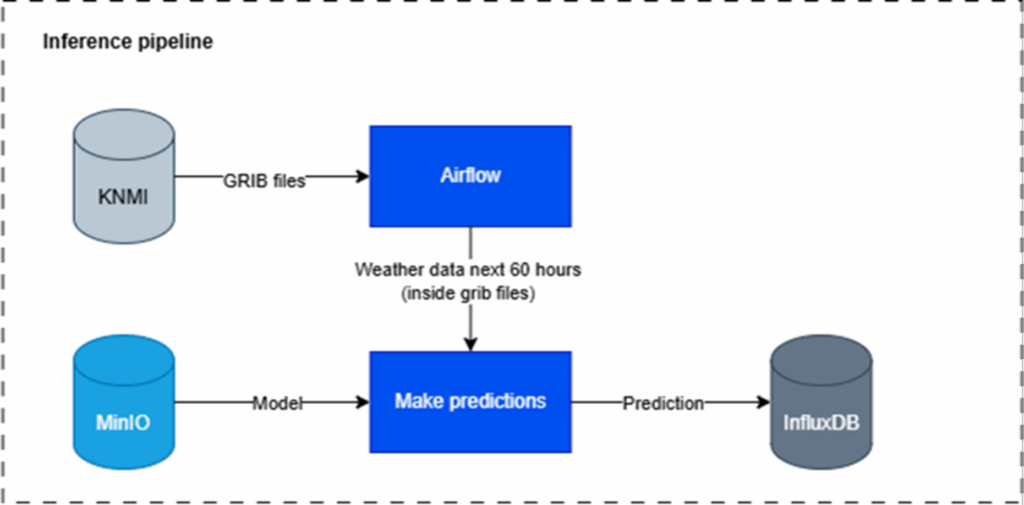
Data Preparation
Since we download approximately 1GB of weather forecast data every hour, it is crucial to identify and extract only the most relevant subsets to keep the pipeline efficient and manageable. Through targeted data preprocessing we minimize unnecessary processing, reduce storage overhead, and improve the overall accuracy and performance of the pipeline by eliminating noise and potential inconsistencies early in the workflow.
Data Structure
Because KNMI relies on technology that is around 20 years old, the main challenges lie in the data processing. They use GRIB files, where the data is represented as a map divided into a grid. Each grid cell contains approximately 50 different variables, measured at various heights and with different parameters.
Because we only care about the grid cells inside the Netherlands, we developed a custom conversion from coordinates to Netherlands’ postal codes to be able to predict better the users’ future consumes of energy.
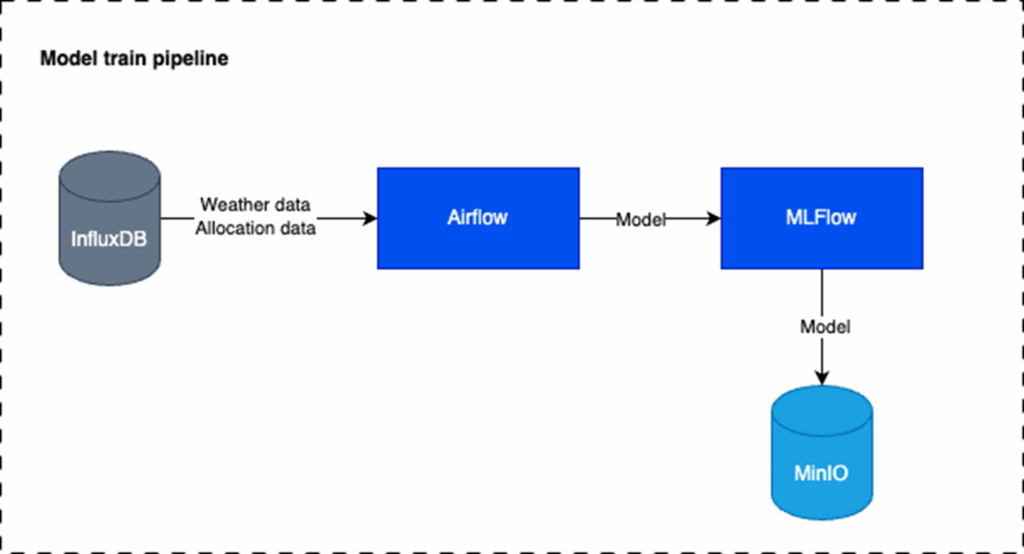
Model Training Pipeline
When the actual allocation data becomes available, we manually trigger the model training pipeline to update the model using the latest and most accurate information. While this process is expected to be automated in the future, we currently lack direct access to the allocation data. As a result, the data must be manually uploaded and inserted into the database each time it is provided to us, adding an extra manual step before retraining can take place.
Conclusion
We successfully implemented a new pipeline that is easier to scale and better to monitor. While the quality of the model is naturally limited by the available KNMI data, the primary achievement of this project lies in establishing a robust and future-proof pipeline. This foundation ensures that as more data becomes available, the system can grow and improve efficiently.

This project has been executed in the context of the Master of Software Engineering – Saxion Hogeschool
Geef een reactie
Je moet ingelogd zijn op om een reactie te plaatsen.